之前看过一句话,未来领域类专家需求将越来越少,而相应的数据挖掘专家需求将不断增加,这时因为深度学习的核心在于其自适应的特征提取。PCANet是一个基于CNN的简化Deep Learning模型。之所以读它是因为它是基于PCA(SVD)的,其卷积核从图像信号的某种SVD分解得到的,而这也是张量列分解的核心之一。与CNN相比,该网络卷积核是直接通过PCA计算得到的,而不是像CNN一样通过反馈迭代得到的。
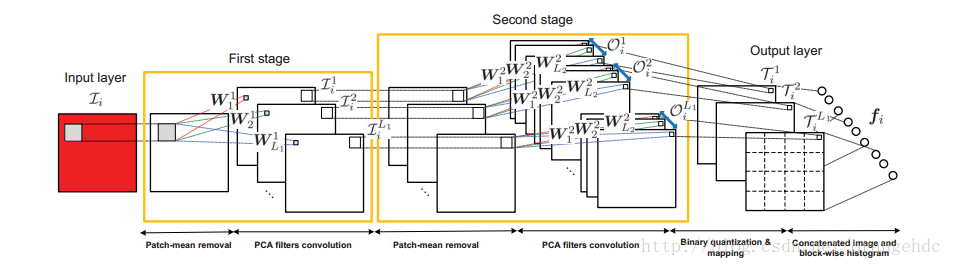
从上图可以看到,PCANet的训练分为三个步骤(stage),前两个stage很相似,都是去平均,然后PCA取主成分并卷积,最后一步是二值化和直方图量化。下面按步骤介绍PCANet的训练过程:
一、特征提取
1、First stage:
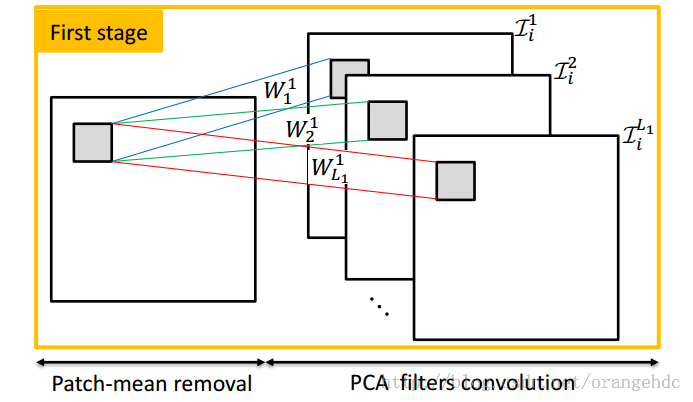
1)、选取一个\(k_1 \times k_2\)的窗口(通常为\(3 \times 3\)、\(5\times 5\)、\(7\times 7\))来滑动选取图片的局部特征。每张\(m\times n\)大小的图片\(I_i\)经过滑动窗口提取局部特征之后,就变成了\((m-k_1+1)\cdot (n-k_2+1)\)个k1k2大小的patch(注:在论文中patch个数是mn,代码中是(m-k1+1)(n-k2+1), 为方便书写,以下都写为mn),将其写成\(k_1k_2\times mn\)列的矩阵\(B_i\),每一列代表一个局部特征patch。相应的滑动选取公式为:
其中\(j=j1+(j2-1)*(m-k1+1)\).
2)、将以上矩阵按列进行去平均,便完成了对单张图片的特征提取操作。
3、对所有N张图片执行以上操作,将特征并排在一起,得到一个新的数据矩阵X,每一列含有\(k_1k_2\)个元素,一共有Nmn列。
4、对这个X矩阵做PCA,取前L1个特征向量,作为该步骤的filter。
5、把这L1个特征向量的每一列(每一列含有\(k_1k_2\)个元素)重排列为一个patch,这样就得到了L1个\(k_1\times k_2\)的卷积核\(\{W_l^i\}_{l=1}^{L1}\)。
6、然后就是对每一张图片,都用这L1个卷积核做一次卷积。\(I^l_i=I_i \star W_l^i\)
2、 Second stage:
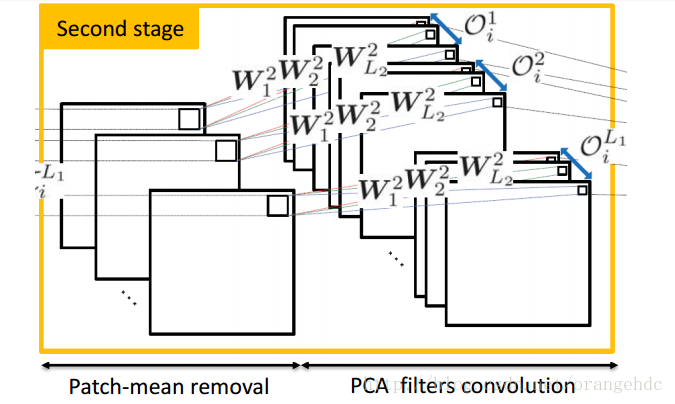
步骤同first stage,此时输入图片数为N*L1张,通过PCA得到L2个卷积核,输出\(NL1L_2\)张图片.
3、Output layer: hashing and histogram
Hashing: 二值化
首先是对Second stage的每个卷积的结果做二值化,每一组得到L2张二值图片,对这L2张二值图片进行十进制编码,得到一张新的十进制图片,元素取值范围为[0, \(2^{L1}-1\)]
Histogram:直方图统计
对每L1张图片做histBlock到vector的变换,假设对原图\(128\times 48\)的图选取\(32\times 32\)的histBlock,overlap系数0.5,原图有14个histBlock,将histBlock变换为vector,得到\(1024\times 14\)的矩阵。对这个\(1024\times 14\)的矩阵做直方图统计,因为选了256个区间,所以得到的Bhist矩阵大小为\(256\times 14\)。最后将这个矩阵转化为$28672(L1=8,28672=256\times 14\times 8)维的vector,这样就完成了一张图片的PCANet的特征提取。
二、分类器训练
将列向量放到训练好的SVM中进行分类
三、论文及代码下载:
论文:http://arxiv.org/abs/1404.3606v2
matlab代码:https://github.com/alanhuang1990/PCANET
c++代码:https://github.com/Ldpe2G/PCANet
亦可在我的百度网盘分享中下载: 链接, 提取密码为(67nw).